咱们都知道,英伟达在硬件上卖 GPU 算力,软件方面手握 CUDA 生态,都快把显卡和 GPU 计算这门 “给 AI 卖铲子” 的生意给垄断了。
可以说在 GPU 编程这件事上,CUDA 几乎就是 “版本答案”,以至于之前行业里形成了一种共识:想要真正发挥显卡的性能,基本绕不开 CUDA,自然也就绕不开老黄的显卡。
但是前一阵老黄发了个 GPU 编程的新技术,居然是反过来向中国 “取经”?
事情是这样的,上个月初英伟达毫无征兆地推出了一个叫 CUDA Tile 的 GPU 编程语言,直接让圈里人炸锅了。因为官方是这么形容这次更新的, “这是自 2006 年 CUDA 发布以来,最大的一次进步”。

那为什么说老黄这个技术是在向中国取经呢?因为 2024 年的时候,刚有一个中国团队开发过和 CUDA Tile 思路非常相似的 GPU 编程语言 “TileLang”。
并且前段时间 DeepSeek 发布 V3.2 的时候,真的同步发布了两个版本 —— 一个 CUDA 语言构建的版本,一个 TileLang 语言构建的版本。
曾经 DeepSeek 只发布 CUDA 语言构建的版本,甚至为了榨干硬件算力,不少代码用的还是英伟达专有的 PTX 汇编语言,导致过往的 DeepSeek 模型与老黄的运算卡深度绑定。
但是中国团队开发的 TileLang 编程语言不挑运算卡,所以 DeepSeek V3.2 可以很轻松的部署在华为昇腾等国产运算平台上。
所以事情开始变得有意思起来了。。。由于 TileLang 发布、DeepSeek 使用 TileLang、CUDA Tile 发布这几个事儿前后脚挨着,托尼就在网上看到有种说法:老黄是感受到国内厂商的威胁了,这才开始 “抄作业”。

那么真相到底是不是这样呢?一个 GPU 编程语言,就能动摇英伟达的根基了?
真不怨网友们唱衰老黄,托尼身边熟悉 GPU 编程的人,最近几年也都在吐槽一件事:现在的 CUDA,好像有点跟不上 AI 时代的节奏了。
过去 CUDA 之所以让大家觉得效率爆炸,靠的其实是一套非常省事的工作方式,叫 SIMT (单指令多线程)。简单说,就是 GPU 发一条指令,就能让一大堆线程同时行动。
就拿 FPS 游戏举例,当对面朝你扔了一颗闪光弹,GPU 干的活很简单:对着屏幕上几百万个像素,重复同一套操作 —— 算亮度、填颜色,让画面瞬间变得“晃眼”。
渲染管线(顶点→像素)着色过程
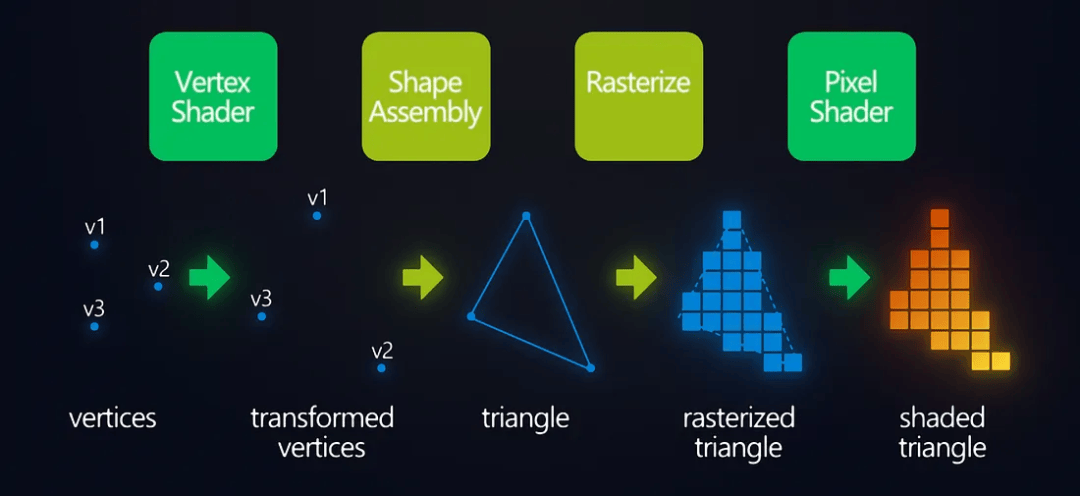
其实不光是“像素着色”这种活儿,实际上在图形渲染和通用计算的时代,交给 GPU 来处理的工作,都可以理解为类似的流水线作业: 任务单一、步骤固定、数量还多。GPU 最擅长的正是这种一件规则完全一样的事,同时做成千上万遍。
但到了 AI 时代,GPU 发现天塌了,因为 AI 推理不像渲染那样,一眼就知道接下来要干啥,而是要“摸着石头过河” —— 后面的计算,往往得等前一步的结果出来,才能决定。
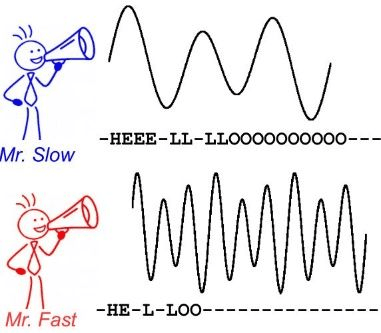
问题在于,SIMT 这套机制一点没变,GPU 还是那套老习惯:一组线程,必须听同一条指令,按同一个节奏往前走。所以就出现了线程之间彼此看眼色,快的等慢的、算完的等没算完的,GPU 的效率就被浪费了。
而且还有一个更现实的问题:在 AI 推理中,很多运算的中间结果会被反复使用,但 CUDA 的执行模型并不关心数据复用,一轮线程执行结束,结果就会被写回全局内存。
所以 CUDA 编程被吐槽难写、跟不上时代,就在于写代码的人不光要懂算法,还要把线程的 “组织架构和分工” 排明白: 哪些线程负责搬数据,哪些线程负责计算,什么时候同步,全都要程序员手搓完成。。。搞不好就造成 GPU 的效率打折扣。
其实英伟达很早就意识到了 CUDA 对 AI 不友好。所以在 2014 年的时候,老黄又端出来了一个叫 “cuDNN” 的玩意,它的思路非常直接 ——
既然很多 AI 算子大家用 CUDA 从头写,既复杂又容易出错,所以干脆先让英伟达的工程师们,把最常用的几种计算,比如卷积、矩阵乘,全部提前写好,再封装成开发者可以直接调用的内核。

换句话说,cuDNN 就是一些 AI 推理模型的 “工业预制菜”,程序员只管点菜,GPU 内部怎么跑、怎么调,交给 cuDNN 自己处理。
所以 cuDNN 的缺点也很明显:AI 研究员永远只能点菜单上的菜。一旦模型里出现了新算子,对于 cuDNN 来说考题就超纲了。。。这时候 AI 研究员还是要回到 CUDA,重新和线程、内存、同步这些底层细节打交道。
而 TileLang 的出现,改变的正是这一点。它并不是再多做一份“预制菜”,而是直接把原来程序员要干的那一大堆“调度”杂活 —— 线程怎么分、数据怎么复用、什么时候同步,全都接了过去。
左图-从整体看任务拆分,右图-从局部看线程如何逐元素执行;CUDA的线程思维 thread-level 属于右边这种~
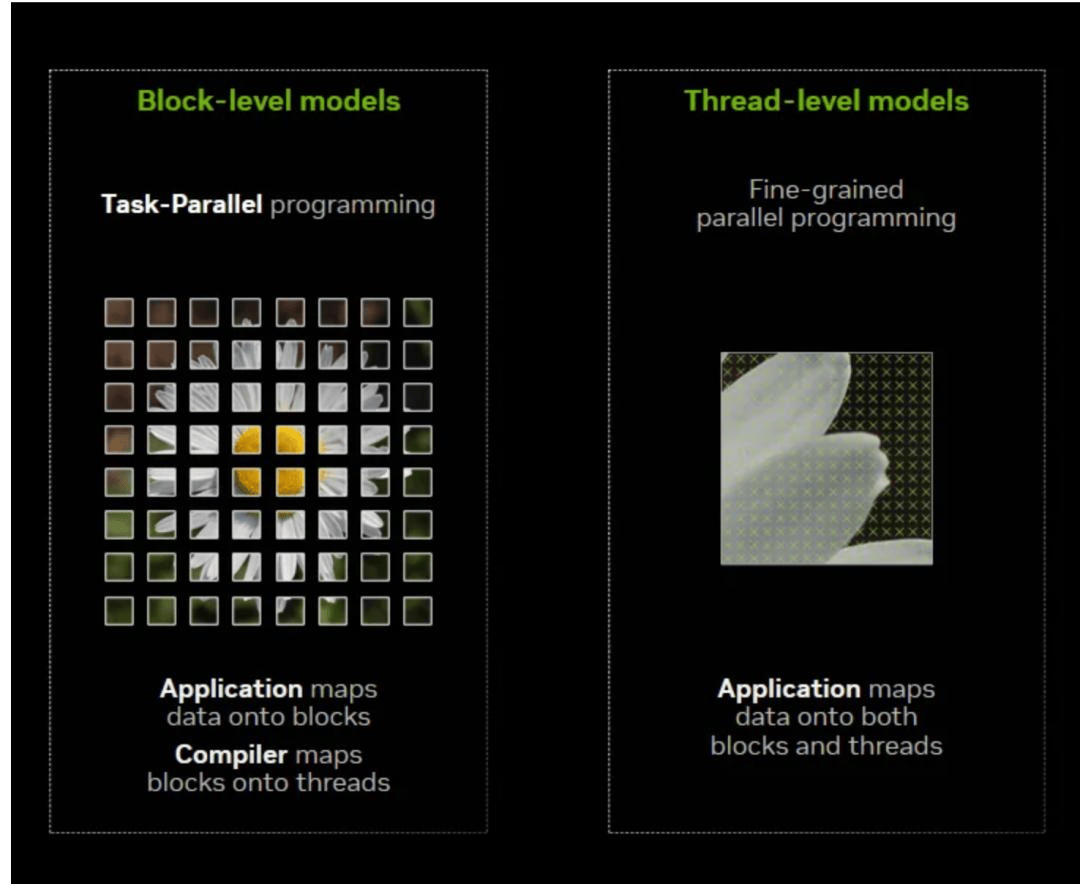
这下开发者只需要告诉 TileLang:想做什么计算,用哪些数据,怎么算。至于这些计算怎么映射到具体的 GPU 硬件和线程上,统统交给编译器去完成。
结果就是,即使是 cuDNN 没覆盖的新算子,程序员也不必再回到手写 CUDA 的老路上。代码更少,逻辑更清楚,性能也更容易跑出来。
根据官方示例,在一些算子开发中,TileLang 可以把 CUDA/C++ 的代码量从 500 多行压缩到约 80 行,同时性能反而提升了约 30%。过去“又累又慢”的 GPU 编程,这一次在开发效率和运行性能上,都吃到了 TileLang 带来的红利。
在 H100 显卡上,计算 MLA 算子,TileLang 性能接近目前最快的 FlashMLA
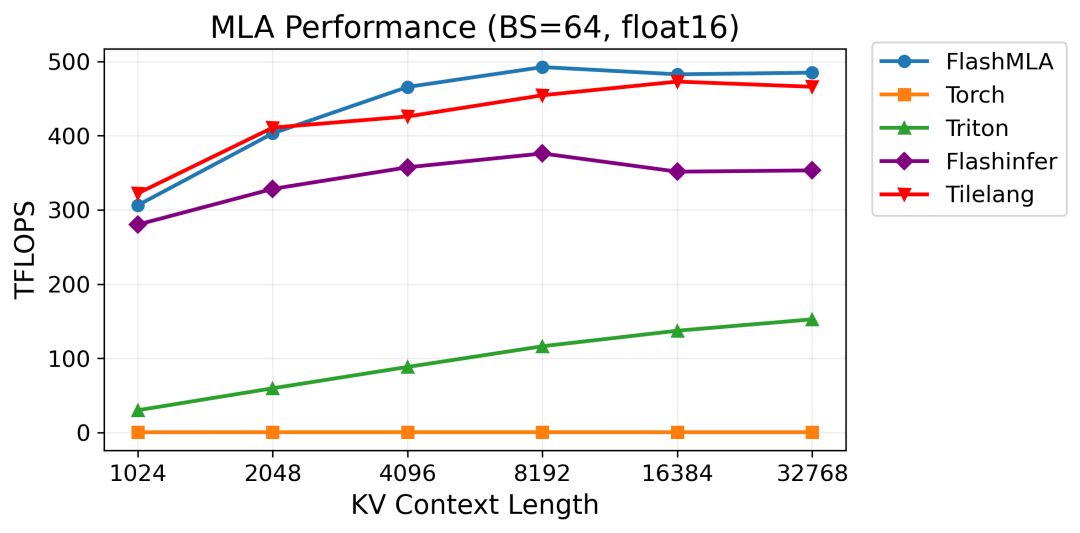
更关键的是,TileLang 这类工具还顺手验证了一件以前大家不太确定的事 ——
只要编程语言能把计算逻辑表达清楚、编译器足够聪明,不用手写 CUDA 这种底层代码,GPU 同样可以跑得很快。
事情发展到这里,英伟达其实已经很难继续保持观望了。
所以去年 12 月英伟达亲自下场,推出了 CUDA Tile,你可以理解为英伟达官方版本的 TileLang。
这个动作传递的信号其实非常明确:与其让开发者依赖第三方 GPU 语言,慢慢摸索 “GPU 还能怎么用”,不如这件事,英伟达自己来干。
作为英伟达的第一方 GPU 语言,CUDA Tile 掌握着最短最直接的优化路径。在可预见的未来,如果想在英伟达 GPU 上,榨干每一分性能,那 CUDA Tile 大概率会是最省事、也最稳妥的选择。

要说 CUDA Tile 一出来,TileLang 就没戏了?那也不至于。
因为 CUDA Tile 再强,也有一个前提:你打算一直用老黄的显卡。
而 TileLang 的最大价值,就在于它不被任何一家硬件厂商绑定 ——
因为过去大家买显卡,关注的是:“这张卡的 CUDA 生态成不成熟,写编程时的现成工具多不多?”
但当 TileLang 这种写法越来越常用之后,问题可能会变成:“我现在这套用 TielLang 写的代码,换一张卡还能不能继续跑?”
无论是 AMD 的 GPU、谷歌的 TPU,还是国产 AI 芯片,只要 TileLang 跑得通,那么 AI 模型和算子,就不再必须按照 CUDA 的方式来写,开发者就不用为了换平台,把模型和算子推倒重写一遍,相当于所有训练模型的人都拥有了 “自己挑铲子” 的能力。
类似的故事我们并不是第一次见到。
游戏市场里, DirectX 12 已经和 Windows 深度绑定,可以在 Windows 平台上性能发挥到极致、工具链和优化经验也非常成熟,但这并没有阻止 Vulkan 这样更开放、更跨平台的技术,逐步分走开发者的声量和生态位置。
开发者用脚投票的结果已经证明了,性能并不是唯一标准,开发者为了不被单一厂商的技术路线“卡脖子”,有时候也会主动选择更开放的技术路线。。。
撰文:Levi
编辑:米罗 & 粿条 &面线
美编:焕妍
图片、资料来源:
英伟达官网
mashdigi.com
tilelang.com
medium.com
csdn @Wanderer001 —— CTC(Connectionist Temporal Classification)介绍

