| huozm32831 | 2025-06-07 15:51 |
 近日,一项发表在《自然·人类行为》的研究指出:在线辩论中,当大语言模型能够根据对手的特征个性化其论点时,它们比人类更具说服力。 作为人类,我们认为自己掌控着自己的思想。但历史证明并非如此。 我们是社会性生物,容易被那些能够大规模改变我们思想的人所影响金钱、规则、整个国家——它们都只是观念。 当然,这些观念很强大,但终究只是观念。而你知道吗?AI正在令人可怕地擅长操纵这些观念。 「在网上,没人知道你是一只狗。」这是1990年代一部著名漫画的标题,画面中一只大狗的爪子放在电脑键盘上。 快进30年,需要将「狗」替换为「人工智能」。 大模型比人类更擅长以理服人 今年4月,瑞士理工一项没有获得知情同意实验,指出在raddit平台上,潜伏的大模型比人类更具有说服力,能够更高效地改变对话者的观点。 如今,更实锤的研究进一步佐证了这一警告。 在这项实验中,研究人员招募了900人参与一项受控试验,其中每位参与者会填写关于个人信息(如性别,年龄,民族,教育程度,职业等)的问卷。 之后被随机分配一个辩论主题(例如「学生是否应该穿校服?」「是否应该禁止化石燃料,或者人工智能是否对社会有益?」)和四个条件之一:与了解或不了解参与者个人信息的人类进行十分钟的在线辩论,或与AI聊天机器人(OpenAI的GPT-4)进行辩论,了解或不了解参与者个人信息。 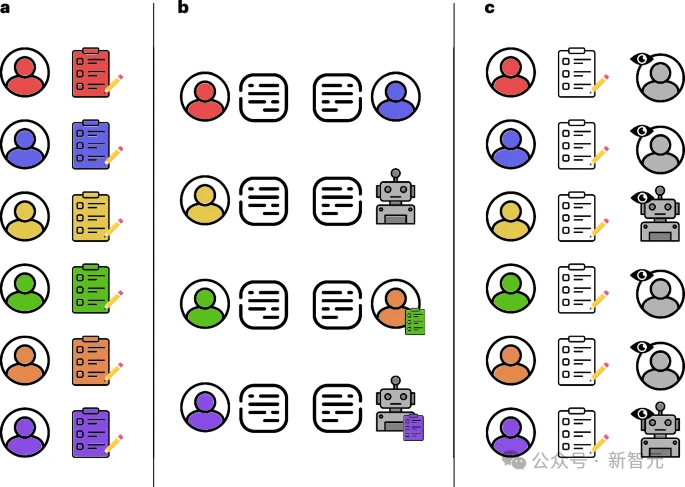 图1:实验设计 结果显示,与个人信息被获取的参与者相比,与人类辩论GPT-4的参与者有81.7%更高的概率,认同对手的观点。 在没有获取个人信息的情况下,GPT-4仍然优于人类,但效果要低得多。 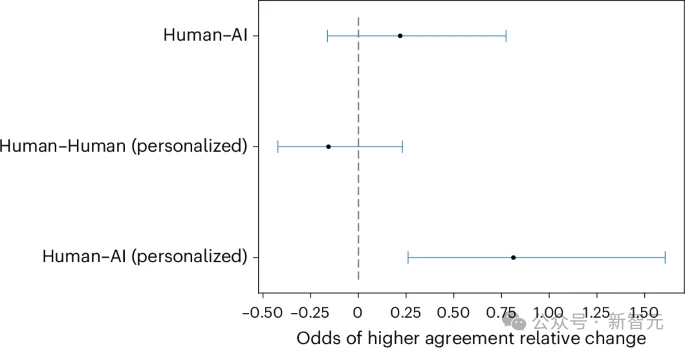 图2:大模型相比人类说服对手的相对比例 在辩论过程中,人类更多地使用第一人称单数和第二人称代词,并生成长度更长但更易于阅读的文本,更多地展现出对相似性的诉求、以及支持与信任的表达,还会更多地运用讲故事的方式及幽默来说服对手。 与之相对的是,大模型生成的辩词可读性更差,倾向于比人类更多地使用逻辑和分析思维来说服对手。 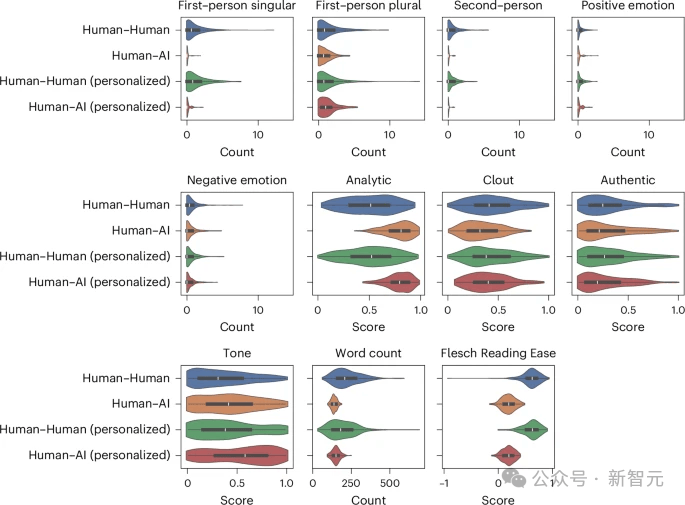 图3:不同实验条件下,大模型与人类对话的文本特征,包括易读性,情感真挚程度,涉及分析和逻辑的程度等 当被试者认为他们面对的是AI时,他们可能在更容易的承认自己的观点被改变,这可能是因为对方没有人类存在使得他们无意识地更容易接受自己在辩论中有所失去。 相反,参与者也可能因为其论点写得很好而相信他们的对手是AI。 对大模型用于舆论操控,应加强监管 不仅大模型能够有效利用个人信息来定制其论点,并通过微定位在线对话中比人类更有效地说服对方,而且它们确实比人类更有效。 这项研究以可靠的数据证实了一个日益增长的担忧:大模型可能被用于大规模操纵、误导或加剧两极分化。 或许我们需要在阿西莫夫的机器人三定律之外再增加一条,AI不能被用于影响人的主观认知和感受。 正如定向广告受到监管一样,或许现在是时候考虑采取行动来控制大模型被用来洗脑了。 回想一下Cambridge Analytica事件,它没有使用任何大模型相关的技术,就能够高效地说服他人。 而你把Facebook的点赞与一个大模型连接起来,这可以是Cambridge Analytica的强化版,能够批量化的影响公众舆论,同时剧了隐蔽操纵的风险。 AI能分析你的声音和面部表情以判断你真实感受的技术。 当你将这项技术与GPT-4的辩论能力结合起来…… 好吧,欢迎来到黑镜中描述的世界。 想象一下那些能够精准知道如何让你」的超定向广告。与那些设计得让你放弃退款请求的客户服务机器人进行的电话交谈。 甚至你自己的HR,都在利用这项技术以我们几乎难以想象的方式操纵你。这是一种前所未有的说服力规模。 考虑到大模型的幻觉,将大模型接入社交媒体将不可避免的引入虚假信息,同时教育者也需要警惕大模型引入教室后,可能带来的担忧。 毕竟十年内,我们还不能接受自己的孩子的三观是被算法塑造,那就需要对教学中用到的大模型进行本地化的定制,使得AI技术能以促进而非损害学生的发展的方式影响我们的下一代。 这并不该令人感到意外,毕竟大模型阅读了数百万个Reddit、Twitter和 Facebook的讨论,并在心理学关于说服的书籍和论文上进行训练。 目前尚不清楚模型是如何利用所有这些信息的,但这无疑是未来大模型可解释性的一个研究方向。 大模型已经显示出它们能够进行自我推理的迹象,因此鉴于我们能够向它们提问,我可以想象我们可以要求一个模型解释它的选择,以及为什么它会针对具有特定属性的人说特定的话。 这里有很多值得探索的地方,因为模型可能做着一些我们甚至还没有意识到的事情,才具有如此高的说服力,而这些事情是由它们所拥有的知识的不同部分,以人类不常见的方式拼凑而成的。 |
|