| 厨爹 | 2024-06-15 15:00 |
|
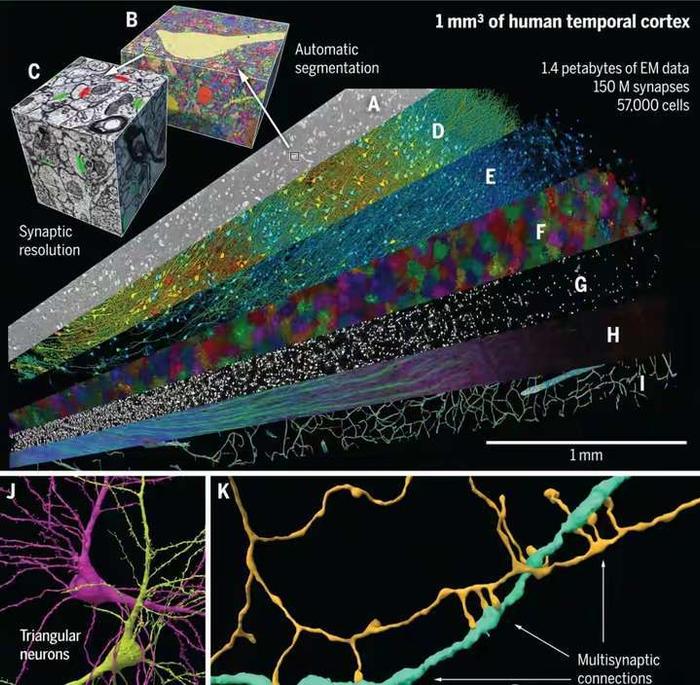
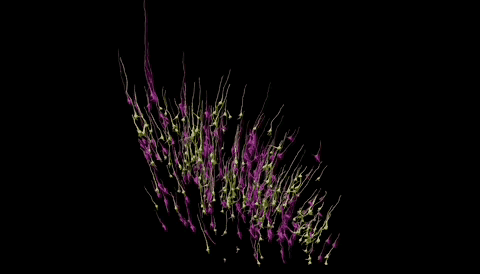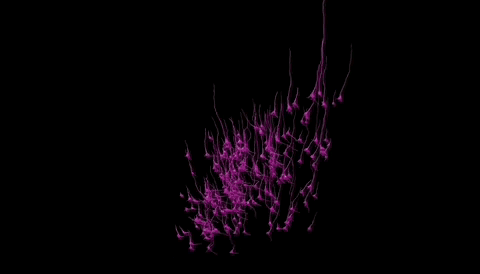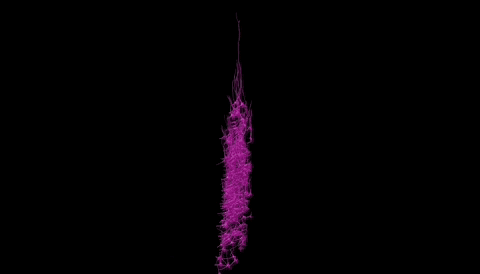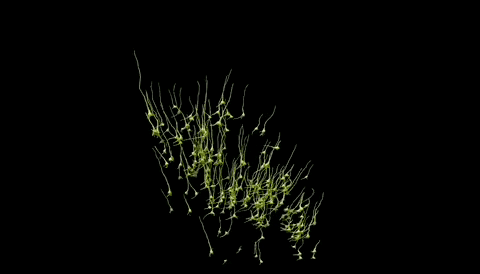
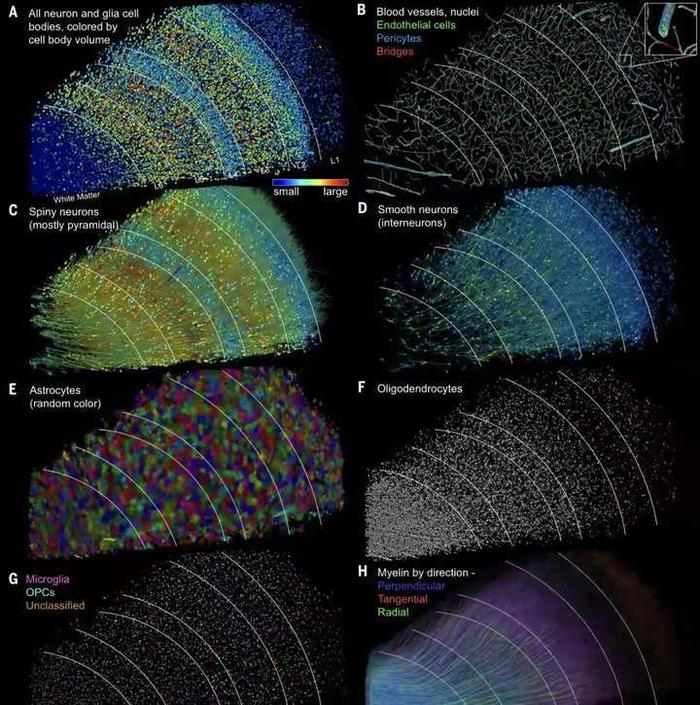
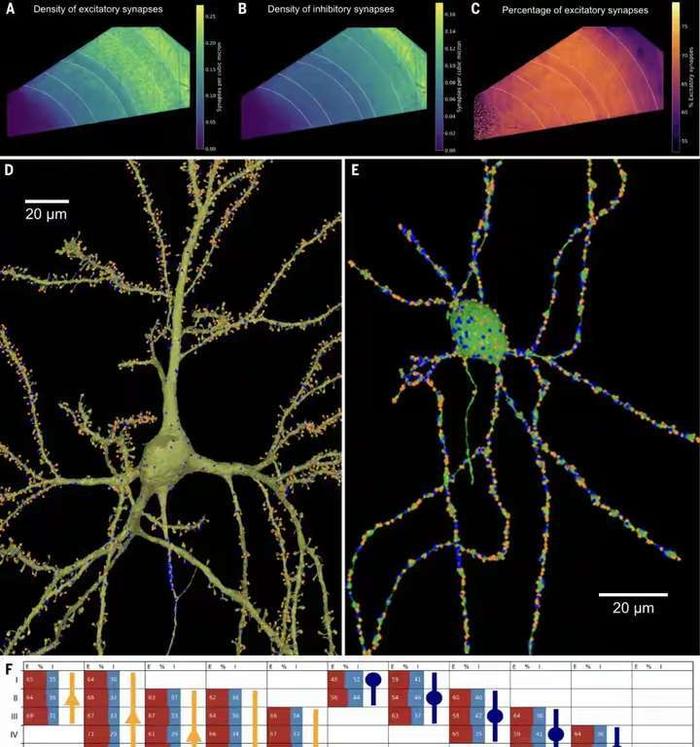
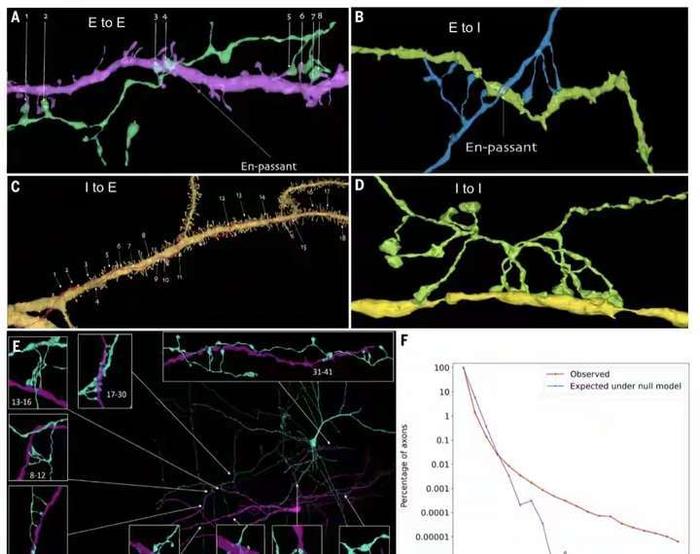
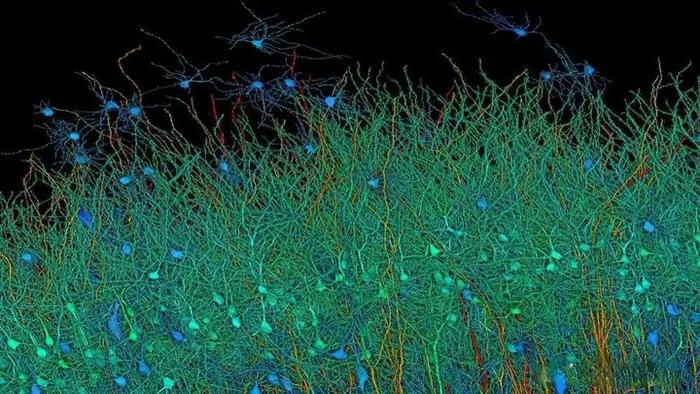
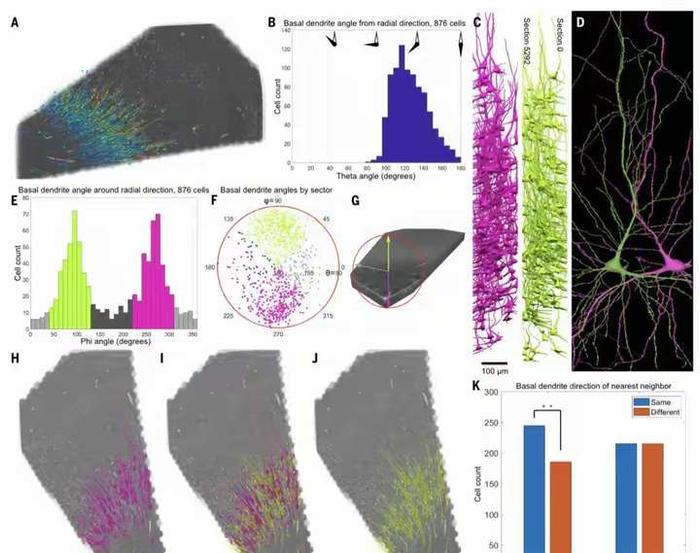
在神经科学的领域里,一场革命性的突破正在悄然发生。人脑的构造有多复杂?功能有多强大?近日谷歌与哈佛大学的脑科学研究人员联手,成功地对1立方毫米的脑组织进行了纳米级建模,居然存储了1400TB的惊人数据。 我们平时接触的数据量,很少会到TB的级别,因为1TB等于1024GB的容量,基本上也就是如今普通电脑的硬盘容量,那么1400TB也就等于143.36万GB了,而这只是一立方毫米的脑组织的建模数据存量。 一立方毫米的脑组织的体积,也就像一个小米粒的大小,科学家们却在其中发现了5.7万多个细胞,1.5亿个神经突触,230毫米长的微小血管等,各种精细结构不计其数,让人十分惊叹脑组织结构的复杂程度。 这项名为H01的重建项目,首次以纳米级的分辨率展示了人类大脑中的突触连接网络。这项研究的核心是一个来自45岁女性癫痫患者的颞叶皮层组织样本,大小约为1立方毫米。通过一系列精细的处理过程,包括快速固定、染色和树脂包埋,样本被切成了数千个超薄切片,每个切片的厚度仅为33.9纳米。之后研究者利用多束扫描电子显微镜对这些切片进行了成像,获得了总大小约1.4PB的原始二维图像数据。 通过这种超高分辨率的成像技术,科学家们得以观察到以前从未见过的细节,包括神经元之间的细微连接和细胞内部的复杂结构。通过对这些结构的分析,研究者们鉴定出了该脑区的主要细胞类型组成,并发现了一些以前未知的神经元形态和连接方式。 在获得了如此庞大的数据量后,研究者们使用计算工具对这些二维图像进行了拼接、对齐,并重建出了三维的体素数据。接下来,他们运用机器学习算法对体素进行神经元形态分割,并通过人工校正分割错误,最终构建出了这1立方毫米脑组织内所有细胞、突触和血管等结构的三维形态。 例如,他们发现绝大多数轴突与其目标细胞仅形成一个突触,但少数轴突却能形成多达50个以上的突触,与目标细胞建立特别强的连接。这种多突触的“强连接”在兴奋性和抑制性轴突中都普遍存在,其数量显著高于随机形成突触时的预期水平。这一发现为我们理解神经元之间的信息传递和大脑的信息处理能力提供了新的线索。 此外,该模型还揭示了大脑中的血管系统,这对于研究大脑的能量供应和代谢过程具有重要意义。通过观察血管与神经元的相对位置关系,我们可以更好地理解大脑中的血液流动和氧气供应对神经元活动的影响。 然而,这一研究的挑战也同样巨大。首先,人脑的体积远远超过了这1立方毫米的样本,要对整个大脑进行建模需要巨大的数据量和计算资源。据估计,要对整个人脑进行建模将产生高达1.76ZB的数据量,这远远超出了目前最先进的超级计算机的存储容量。 其次,人脑中的神经元数量高达数千亿个,突触数量更是高达千万亿级,这使得在模型中进行准确的神经元形态分割和连接分析变得异常困难。 尽管如此,这一研究仍然为我们提供了宝贵的启示和机会。这一成果不仅刷新了我们对大脑复杂性的认识,也为未来的神经科学研究提供了宝贵的数据基础。标志着人类对人脑研究的深入,也为我们理解大脑的工作方式提供了新的视角。 通过不断的技术创新和算法优化,我们有望在未来实现对整个大脑的纳米级建模和深入分析。这将为我们理解大脑的工作机制、预防和治疗神经系统疾病提供新的可能性和途径。 同时,这一研究也展示了人工智能在神经科学研究中的巨大潜力和价值,为我们探索未知的大脑世界提供了新的工具和思路。 |
|