新智元报道
【新智元导读】OpenAI o1推理模型核心缔造者Noam Brown发长文炮轰整个行业:用单一跑分评价AI模型,从2024年就过时了。GPT-5.5看起来只比5.4强一点?控制推理预算后再看,那叫一个天壤之别。
OpenAI的Noam Brown,刚刚发了一篇长文,对着整个AI行业开了一炮。
文章标题叫「大规模推理计算的启示」,核心论点只有一个,你现在看到的所有AI跑分排行榜,给你的信息基本上是错的。
原因很简单。
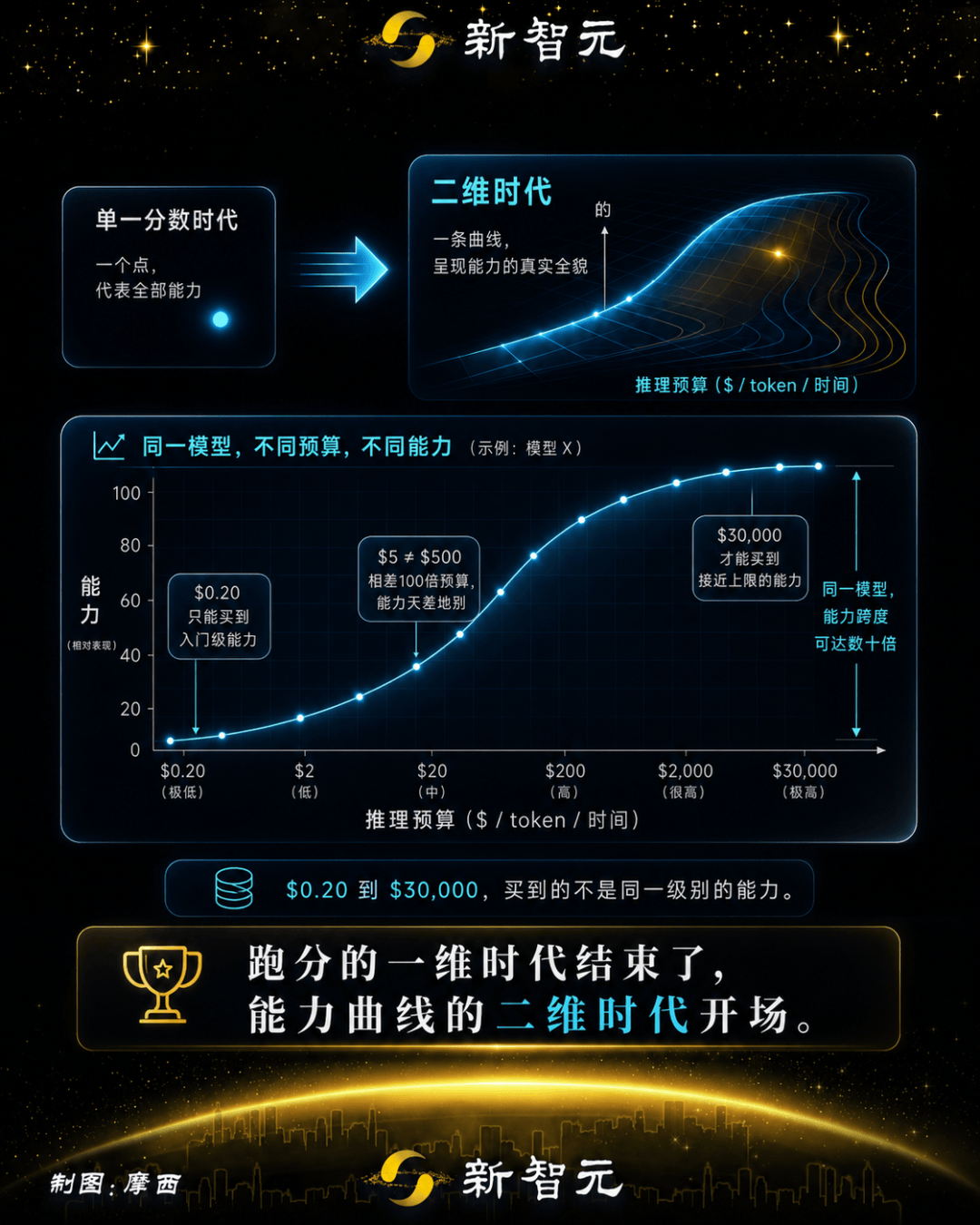
同一个模型,给它一块钱想事情和给它一万块钱想事情,跑出来的分数天差地别。但现在所有的排行榜,都不告诉你这个模型花了多少钱跑出来的成绩。

GPT-5.5的成绩单是「假的」?
4月23日,GPT-5.5发布。
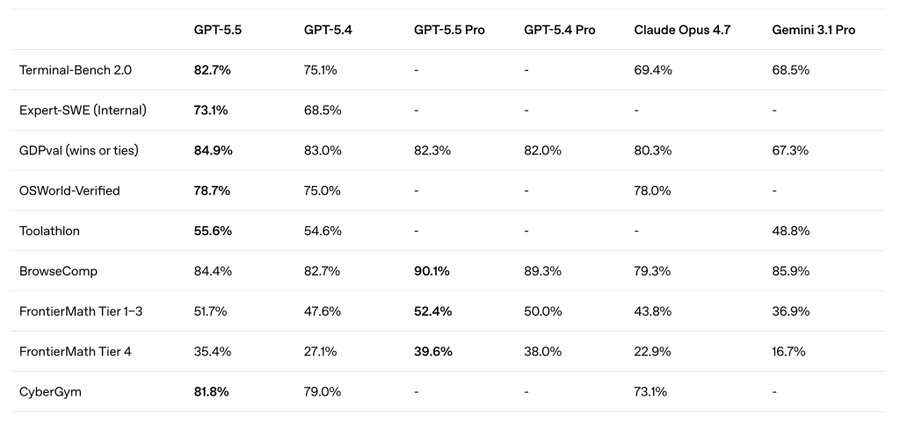
OpenAI甩出benchmark表格,社区照例逐行比对。结论是:还行,比5.4好一点,但也没好到哪去。
然后几个小时过去了。
波兰数学家Bartosz Naskręcki用一条prompt,让GPT-5.5在11分钟内搭出一个代数几何可视化应用。
Ruby on Rails之父DHH更是感慨,用完5.5再切回Opus 4.7,像倒退了一个时代。
同一个模型。benchmark说「还行」,人说「炸裂」。为什么?
原因很简单,5.5和5.4根本不是在同一个计算预算下被测试的。
这就好比两个学生考同一张卷子,一个给了30分钟,一个给了3小时。你拿两份成绩来比,说「差距不大」,这不是比较,这是搞笑。
但benchmark表格上,这两个模型被当成同一个量级来比较,完全忽略了推理预算的差异。一旦控制token预算,GPT-5.5在网络安全评估上大幅拉开GPT-5.4。
Brown在文中展示了两张图。左边是传统benchmark视角,5.5比5.4好一点。右边x轴换成token数量,5.5的曲线远远甩开5.4。
同一场考试。换个维度看,结论完全不同。

这不是个案。
MMLU这个曾经最主流的评测基准,前沿模型全部挤在88%以上,分数差异在统计上已经没有意义。你看到的不是「谁更聪明」,是噪声。
MRCR v2在100万token长度上的测试,GPT-5.4得36.6%,GPT-5.5得74.0%——翻了一倍。但这个维度在标准benchmark表格里根本不存在。

三万美元对两毛钱,同一场考试——「谁排名更高」这个问题本身就已经失效了。
当模型的能力是推理计算量的函数时,一个没有x轴的benchmark分数,就是一个没有单位的物理量。它什么都没告诉你。
在Brown看来,正确的做法是画一条曲线:性能 vs 推理计算量。
x轴可以是token数、美元或耗时,各有优劣。但可以肯定的是,任何一条曲线,都比一个标量数字强。
或者,你也可以设一个明确的预算上限,告诉模型「你就这么多钱,给我答案」。
这恰好是人类考试的逻辑,SAT给固定时间,国际数学奥赛也给固定时间。
只有AI评测,在2026年了,还在假装「给多少钱想事情」这个变量不存在。
被忽略的x轴
为什么这个问题现在才爆发?
因为两年前,推理时计算只是o1的专属概念。
而o1的核心贡献者,正是Brown。
此前,他在卡耐基梅隆做出Libratus和Pluribus(击败顶级扑克职业选手,后者登上Science封面),在Meta FAIR做出CICERO(第一个在策略游戏《外交》中达到人类水平的AI)。
从不完美信息博弈到推理模型,他一直在同一条线上:让AI学会想更久、想更深。
2024年的o1让「推理时间换准确率」进入公众视野。到了2026年,推理时计算已经是所有前沿模型的标配。
GPT-5.5 Pro不是一个独立模型,它是GPT-5.5同一个底座加了并行推理时计算:遇到难题跑多条推理链,综合出结果。
Claude有extended thinking,Gemini有Deep Think,几乎每家前沿实验室都在往同一个方向跑。
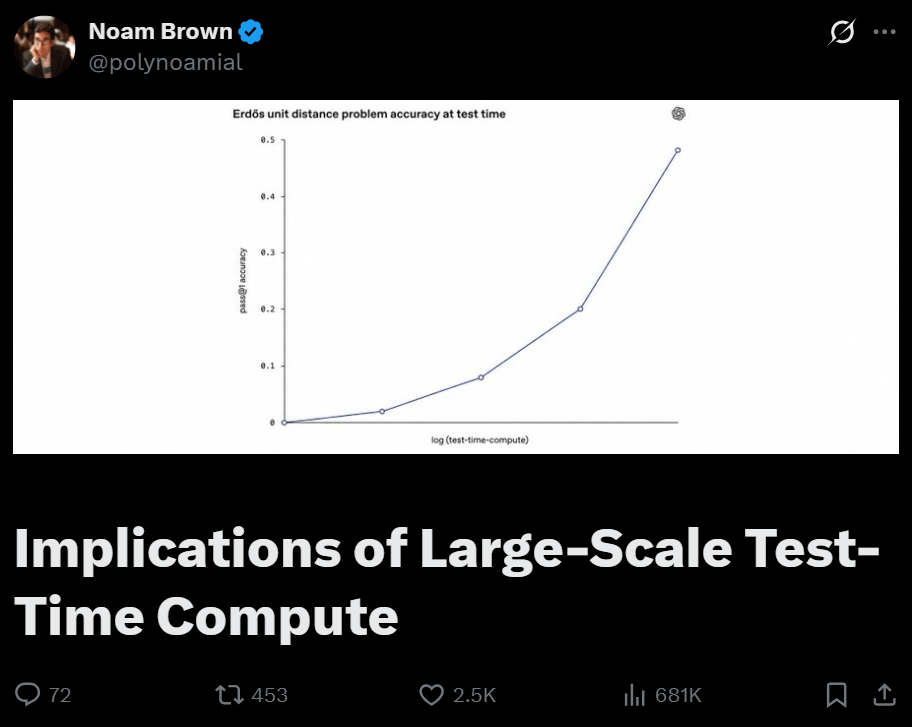
对此,学术界也给出了量化关系。覆盖率与采样次数呈对数线性关系。
也就是,给AI双倍的「想事情时间」,它不会变聪明一倍,但确实会变聪明一点。收益是对数级递减的。
但Brown引用了Karpathy和AI Safety Institute的一个关键发现——
越强的模型,在更长时间跨度上的收益越大。性能的高原期被推远了,甚至可能消失。
弱模型多想两分钟,可能已经到顶了。但强模型多想两个小时,曲线还在往上走。

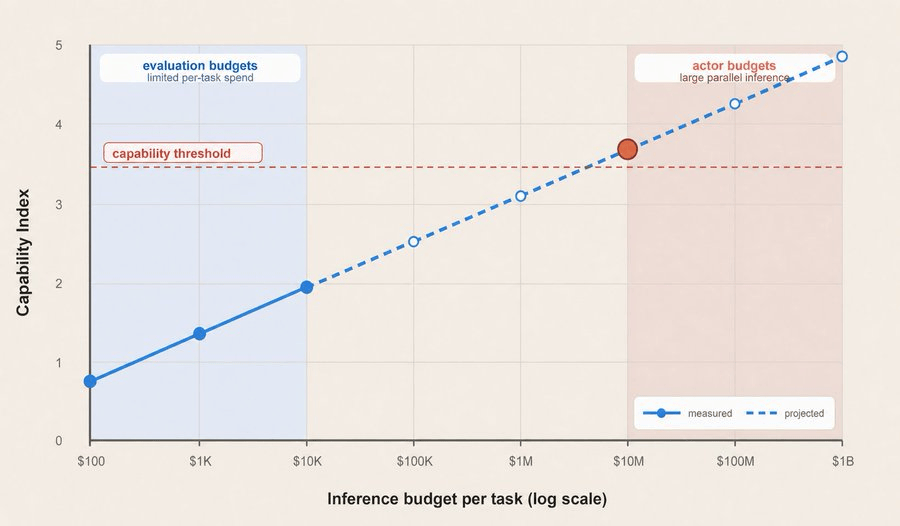
每一代模型发布时,如果你只在某个固定的推理预算下跑benchmark,你看到的就只是冰山一角。真正的能力上限,在你测不起的那片水域。
用Brown的话说就是:「我们可能根本不知道现代LLM的能力天花板在哪里,因为测量成本太高了。」

Brown的三张药方
针对这一问题,Brown给了三条建议。
第一,实验室发布新模型时公布性能-推理计算量曲线,至少标明分数对应的推理预算。
GPT-5.5的82.7% Terminal-Bench 2.0,你不知道花了多少钱跑出来的。你拿它和另一个模型比,你也不知道对方花了多少钱。
这就像两家公司比营收,一家报的是年收入,一家报的是季度收入,但都不标注时间跨度。
第二,benchmark排行榜追踪推理用量,或设定明确预算上限。
ARC-AGI已经在这么做了,但不是行业标准。
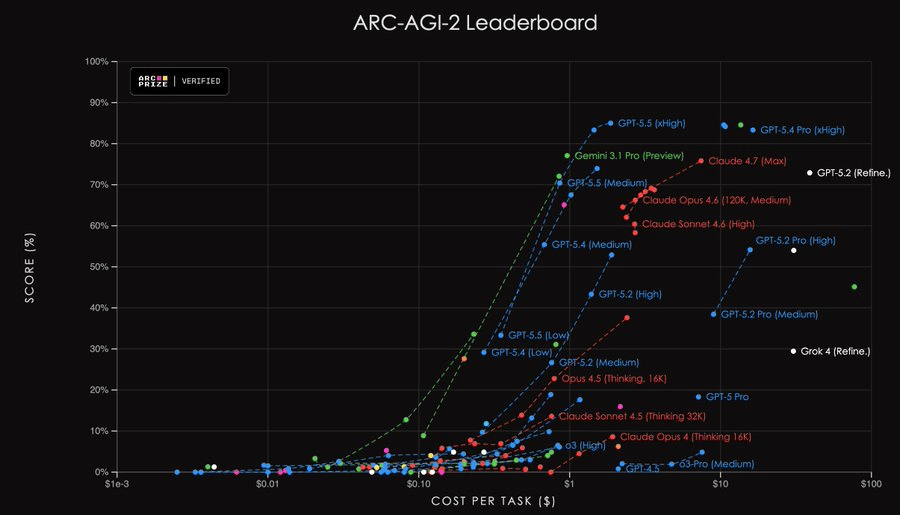
第三, 安全准备框架和负责任扩展政策显式纳入推理计算量。
安全评估不能只测「默认状态」——国家级攻击者完全可以在单个任务上砸1000万美元推理预算。
以Gemini 3 Deep Think为例。
Deep Think本质上就是Gemini 3 Pro加了外部调用框架,任何人花同样推理费就能复现。
真正该问的是,为什么所有模型卡都没把能力作为推理预算的函数来展示?
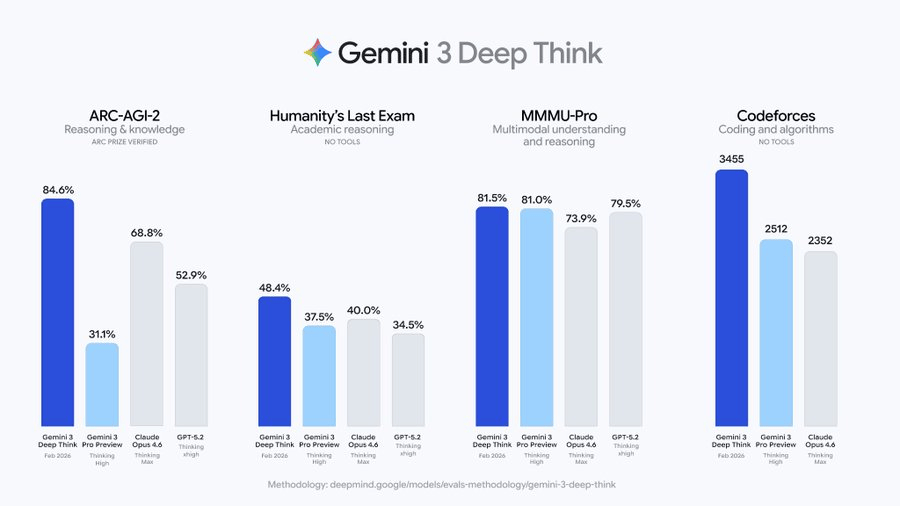
Brown理想中的安全评估应该是一张图。
但他也承认一个棘手的问题,长期评估可能无法靠外推解决。要评估一个AI agent跑一年会不会出问题,可能真得让它跑一年。
而AI实验室很快将面临荒诞局面——agent的运行周期超过了新模型的开发周期。你还没评估完上一代的长期行为,下一代就已经发布了。
超级智能是道算术题
所有前面的讨论都指向同一个问题。
如果模型的能力是推理计算量的函数,而且越强的模型高原期越远,那「超级智能」到底是什么?
传统理解里,ASI是一个质变的拐点:某天某个模型突然在所有认知任务上全面超越人类。
顺着这个逻辑往下想——ASI可能不是一个时刻,而是一条曲线。
前面的数字已经说得很清楚:同一类任务,两毛钱和三万美元的推理预算,买到的是完全不同的结果。但这些还只是已经测过的区间。
没人测过。Brown说了,测不起。
但对数线性的scaling关系告诉你,曲线还没到顶。而且越强的模型,高原期越远。
ASI可能不需要一个全新的架构突破。它需要的可能只是:足够的钱和足够的时间。
一个运行一整年、消耗数亿美元推理预算的AI agent,在这一年里表现出的能力,可能已经在特定领域超越了人类个体的一生积累。
决赛的真实比分
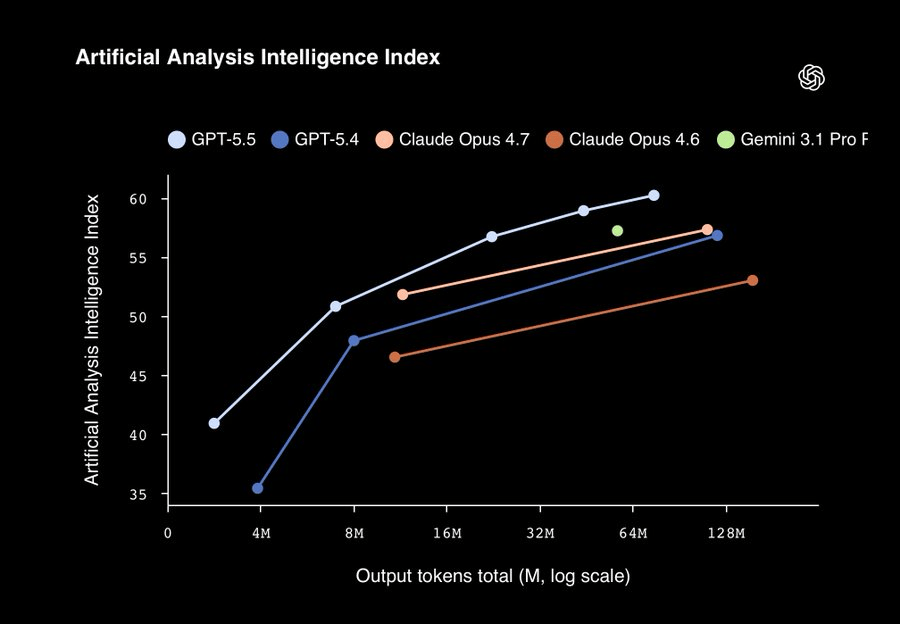
过去十年,整个AI行业习惯了一种评估方式:一个模型,一个分数,排个名次。从ImageNet到MMLU到Chatbot Arena,谁的数字大谁就赢。
如今,跑分的「二维时代」正在开场。
模型的能力从一个点变成了一条曲线,评估从一个分数变成了一张图。y轴是表现,x轴是你愿意花多少钱让它想。
每个「第一」还要再乘以一个变量:推理预算。
2026年,全球科技巨头在AI基础设施上的投入预计接近7000亿美元。这些钱买的不只是更大的模型,还有更长的推理、更多的采样、更快的inference。
当「智能」变成一种可以用美元标价的连续函数,「超级智能」也不再是一个是非题。
谁先适应这个二维坐标系,谁就先看清楚ASI决赛的真实比分。
参考资料:
编辑:摩西
秒追ASI

