以前,大模型拼的是天才。
现在,大模型拼的是组织。
一边是大厂用利润和期权锁人,一边是创业公司去草原守住机房、电力和算力底座。
近日,多家媒体和业内消息称,DeepSeek R1 与 V3 的核心作者之一郭达雅已流向字节跳动;
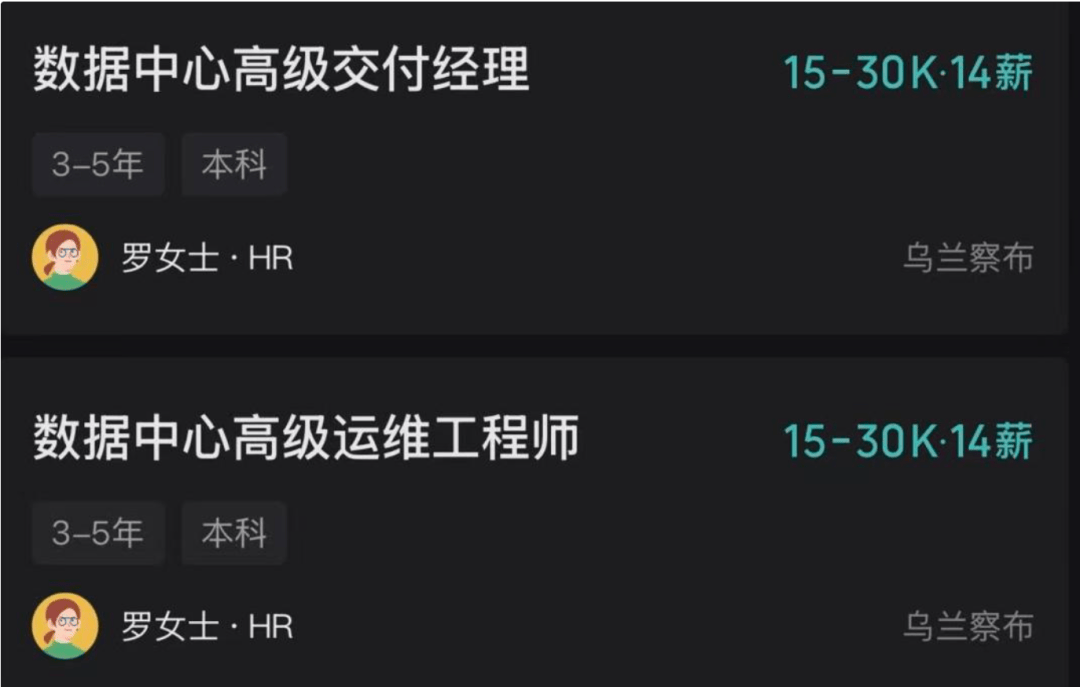
与此同时,DeepSeek 首次把招聘岗位延伸到内蒙古乌兰察布,招的是数据中心高级交付经理和高级运维工程师,月薪15-30K(14 薪)。
这家过去靠效率震撼行业的公司,正在进入全新的下一阶段。
01
一人流动,一场升级
AI 顶尖人才的流动,从来不是单行道,而是一种高频、双向、持续发生的行业常态。
今天的大模型竞争,还远没有进入格局固化的阶段。头部公司之间的人才流动,本来就比外界想象得更频繁。
DeepSeek、字节、Kimi 这样的核心玩家,一边在争夺最强的研究员和工程负责人,一边也在持续向外释放成熟的人才与方法论。
表面看是人在流动,实质上流动的,是代码能力、强化学习经验、后训练流程、数据组织方式,以及把模型能力嵌入真实产品的工程方法。
这是中国AI 产业内部一次次能力再分配,有人从大厂流向创业公司,把成熟的平台经验带到新团队;也有人从创业公司进入大厂,把更锋利的模型训练方法和更极致的效率思路带入更大的资源体系。
这种流动正在持续打破技术孤岛,让先进经验不再封闭在少数团队内部,而是在整个行业中扩散。
过去几年,这样的案例已经越来越多。有人从字节出来后进入DeepSeek,参与预训练数据等关键环节;也有人在字节、Kimi 等公司积累了 post-training 和 RL 的核心经验后,再转向新的创业方向,比如机器人等更具想象力的应用赛道。
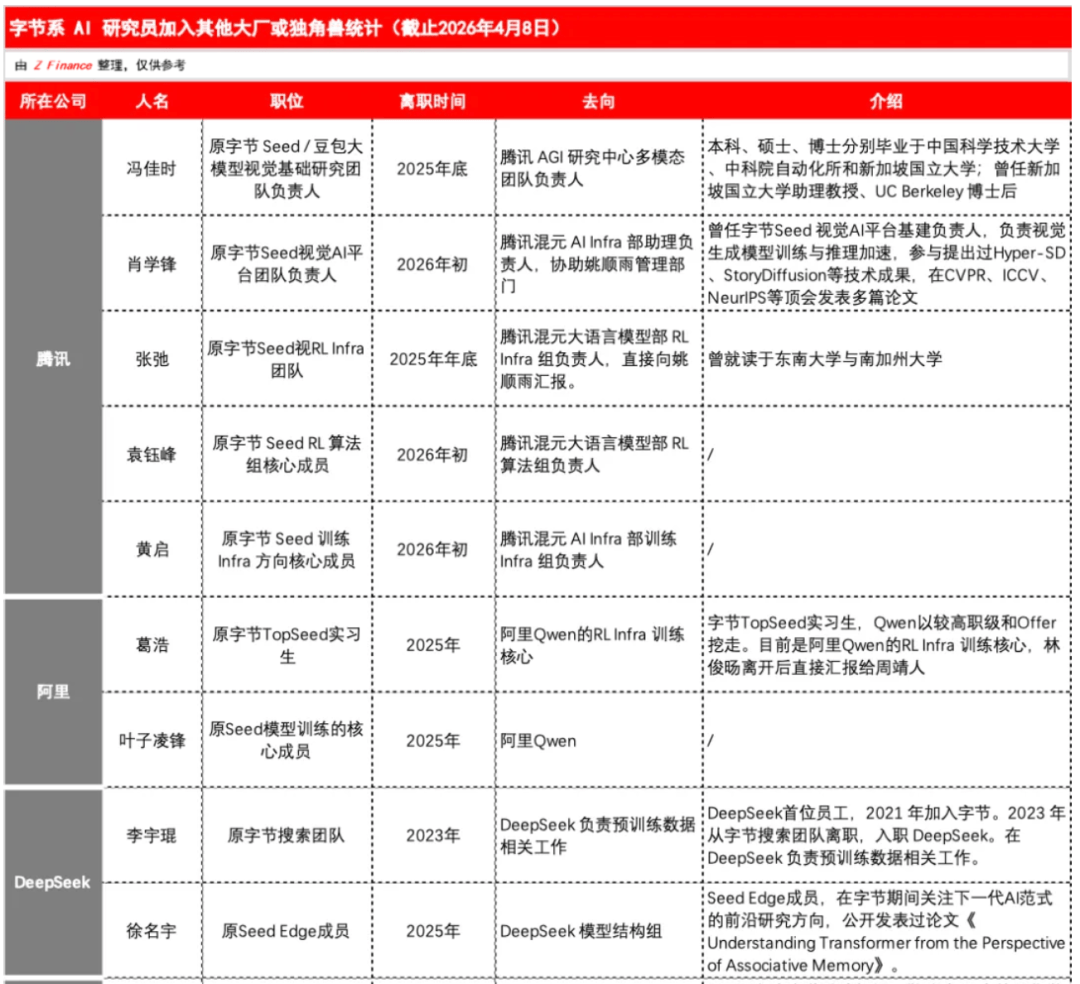
路径不同,但背后的逻辑高度一致:中国AI 的竞争,已经不再只是少数几家公司各自为战,而是在人才流动中不断完成能力迁移、经验复用和新一轮重组。
郭达雅的流动更像是一个缩影,而不是孤例。它提醒所有人,今天AI 行业真正稀缺的,不只是“人”,而是那些经过实战验证的技术链条和工程判断。
真正决定胜负的,也不只是能不能挖到一个明星研究员,而是能不能把流入的人才,迅速沉淀成新的组织能力和产品能力。
02
DeepSeek先赢过一轮
过去一年,DeepSeek 最重要的贡献,恰恰是它先证明了一件事:在算力并不奢侈的条件下,靠架构创新、训练效率和工程优化,也可以把模型能力推到行业第一梯队。
DeepSeek-V3 技术报告指出:模型总参数671B、每 token 激活 37B,全量训练仅用了 2.788M H800 GPU hours。
这个数字的价值,不在于“省钱”两个字,而在于它第一次把“高效率训练”从口号做成了现实。
R1 更进一步。它真正把 DeepSeek 从“会做模型”推到了“会做推理模型”的位置。
官方论文显示,DeepSeek-R1 以 DeepSeek-V3-Base 为底座,通过冷启动数据、多阶段强化学习和后续蒸馏,把推理能力做成了可复制的训练流程。换句话说,DeepSeek 不只是做出一个模型,而是把一条能力路线跑通了。
这也是为什么,今天看DeepSeek,最合理的判断不是“它行不行”,而是“它能不能把已经证明过的效率优势,扩展成更厚的体系优势”。
公司此前披露过V3/R1 推理系统的理论成本利润率可达 545%,但也同时说明,真实收入会显著低于理论值,因为实际业务里存在更低价模型、免费流量和折扣时段。
这里面的关键信号不是利润率有多夸张,而是:DeepSeek 已经摸到了商业化“轮廓”。
03
草原不是浪漫,是底盘
这次DeepSeek 放出的不是普通行政岗,而是数据中心高级交付经理和高级运维工程师,职责覆盖从立项、建设、交付到运营,以及自动化运维平台、资源利用率、SLA 和标准流程。
换句话说,公司组织的边界,已经从“训练代码”延伸到“经营机房”。这不是姿态变化,而是能力结构变化。
而乌兰察布也不是一个带着浪漫想象的地名,而是一张算力底盘。
公开资料显示,当地年均气温约4.3℃,数据中心自然冷却时长可达 10 个月;两条光缆直连北京,端到端时延分别可做到 4.2 毫秒和 6.9 毫秒;同时,乌兰察布已承接北京地区包括 DeepSeek 在内的相关企业算力业务。
对于任何一家需要稳定推理、持续训练和控制总体拥有成本的AI 公司来说,这都不是“草原”,而是基础设施红利。
眼下,即将发布的DeepSeek 下一代 V4 模型正与华为等国内芯片生态深度适配,并在重写部分底层代码。
DeepSeek 接下来面对的竞争,已经不仅是参数,而是芯片适配、供应链协同、数据中心交付和推理稳定性的一整套工程问题。
所以,DeepSeek 去乌兰察布,正在把过去靠效率赢来的先手,转化成一个可持续的算力底盘。
04
竞争规则正在改写
真正改写竞争规则的,还是账本,整个行业正在变重,而且这种“变重”已经写进了财报和资本开支里。
彭博报道称,字节2025 年利润有望接近 500 亿美元,2026 年 AI 基础设施资本开支初步计划为 1600 亿元人民币。
更重要的是,这不是字节一家。阿里2025 年第四季度财报显示,云智能集团收入同比增长36%,AI 相关产品收入已连续第 10 个季度实现三位数增长;
腾讯2025 年全年资本开支达到 792 亿元,全年新 AI 产品相关成本与费用为 180 亿元;
从这些巨头财报里,不难看出:今天的大模型竞争,已经不是单纯的模型发布赛,而是利润池、云基础设施和应用回收能力的综合赛。
这才是DeepSeek 未来真正要面对的环境变化。它率先证明了效率路线的价值,但下一阶段的门槛,正在被云厂商和超级平台用资本开支、数据中心、芯片适配和分发入口一起抬高。
05
把“神兵”变“军团”
一家AI 公司真正的成年礼,不是继续依赖单点天才,而是要能将一次次技术突破,沉淀成梯队、流程和组织能力。
DeepSeek已经来到分水岭,不只是它曾经用更少的资源做出更强的模型,而是它把整个行业逼着重新回答了一个问题:大模型,到底该靠算法赢,还是靠体系赢?
现在答案正在浮出水面:先靠算法打开局面,再靠体系守住胜势。
郭达雅的流动,和乌兰察布的机房,其实是一枚硬币的两面。
前者提醒所有人,顶级人才会在更大的平台和更短的闭环中重新分配;
后者提醒所有人,任何伟大的模型,最后都要落到电力、冷却、芯片、时延和组织调度上。
DeepSeek真正的下一仗,不仅是要做一个更强的V4,更要把自己从“神兵”变成“军团”。
大模型下半场,拼的不再是谁先出一篇论文,而是谁先把论文背后的机房、人才和组织,真正连成一条生产线。

