
智东西
作者 | ZeR0
编辑 | 漠影
全球首款1.8nm芯片,终于正式登场。
智东西拉斯维加斯1月5日报道,在国际消费电子展CES 2026开展前一天,英特尔发布年度旗舰AI PC芯片——第三代酷睿Ultra系列处理器(代号Panther Lake)。

这是首款基于Intel 18A制程(1.8nm级)的计算平台,将AI PC引入埃米时代,端侧AI算力多达180TOPS。
第三代英特尔酷睿Ultra的移动端产品线推出全新英特尔酷睿Ultra X9和X7处理器,均集成了英特尔锐炫显卡,专为满足复杂的多任务处理而设计,能从容应对游戏、内容创作和生产力等复杂工作负载。
其旗舰型号最高配备16个CPU核心、12个Xe核心和50TOPSNPU算力,带来高达60%的多线程性能提升,高达77%的游戏性能提升,并可实现高达27小时的持久续航,已涵盖超过200款PC产品设计。
例如,采用酷睿Ultra X9 388H、电池容量99Whr、采用2.8k OLED的联想IdeaPad参考设计,Netflix流媒体播放续航时间最长可达27.1小时,被英特尔称作“x86续航之王”。

首批搭载第三代英特尔酷睿Ultra处理器的消费级笔记本电脑将于1月6日开启预售,并于1月27日起在全球范围内面市。更多产品设计将于今年上半年陆续推出。
值得一提的是,这款AI PC芯片,还“跨界”了人形机器人。
第三代英特尔酷睿Ultra首次实现了边缘处理器与对应的PC版本同步发布,首次获得了针对嵌入式和工业边缘场景的测试与认证,并将为具身智能、智慧城市、自动化、医疗等领域提供支持。

英特尔称其“已被证明是关键任务边缘和物理AI的理想选择”。
在大语言模型(LLM)性能提升、端到端视频分析、视觉语言动作(VLA)模型中,第三代英特尔酷睿Ultra均有出色的性能表现,在AI推理成本方面也比传统的多芯片CPU和GPU架构更具竞争力。

英特尔正在积极推进边缘AI与具身智能技术的结合,也就是将以往装在PC上的处理器,放在人形机器人、固定机械臂、自主移动机器人等各类机器人上。
在展区,英特尔展出了一台搭载第三代酷睿Ultra的人形机器人。

为了支持这些新兴场景,英特尔与边缘ODM合作推出了参考板和开发套件,集成了英特尔机器人软件套件、工具、框架和应用,并在硬件发布时同步提供。

因此,第三代酷睿Ultra,将成为英特尔史上覆盖最广、全球可用性最高的AI PC平台。
英特尔还宣布,将基于Panther Lake推出一整套掌上游戏设备平台,并将在今年晚些时候由硬件和软件合作伙伴公布更多细节。
本次发布会也是英特尔CEO陈立武在2026年的首次公开亮相。
陈立武分享说,英特尔的使命是让智能具备可获得性、高效率,并实现无处不在的部署。

据他透露,过去一年,英特尔在架构、制造工艺及跨软硬件协同优化方面不断突破极限,已兑现在产品出货方面的承诺,完成了首批基于Intel 18A制程的产品交付。
英特尔高级副总裁兼客户端计算事业部总经理Jim Johnson谈道,整个行业以及英特尔,都在2026年迎来一个战略拐点。英特尔正在基于领先的制程节点,交付有领导力的产品,把计算、图形和AI融合在一起,与客户共同扩展,打造其有史以来最广泛的AI PC平台。

Perplexity CEO兼联合创始人Aravind Srinivas也来到现场,称本地计算将变得越来越重要,主要因为性能、安全、经济性、控制权。基于这些原因,Perplexity将在下个月推出面向企业的AI浏览器Comet。
会后,英特尔客户端计算事业部副总裁兼客户端细分市场部总经理冯大为,英特尔副总裁兼中国区软件工程和客户端产品事业部总经理高嵩,与智东西等媒体进行深入交流。
冯大为分享说,从硬件架构层面来看,Panther Lake实现低功耗的一大方法是低功耗岛,有4个E核(能效核)放在较低功耗区间里,有专属的MagCache,绝大多数非性能型应用都可以留存在低功耗岛里,不会溢出。
高嵩谈道,2026年是PC发展的关键一年,今年就是转折点,谁能在年初推出适应未来PC产品发展的SoC,谁就能够抓住这个转折点。
一、首用1.8nm制程,本地AI算力达180TOPS
第三代酷睿Ultra系列处理器(代号Panther Lake)采用Intel 18A制程,AI算⼒多达180TOPS,融合了酷睿Ultra 200V系列(代号Lunar Lake)的⾼能效与Ultra 200H系列(代号Arrow Lake-H)的⾼性能及扩展能⼒,是一款承载英特尔Agentic AI雄⼼的关键硬件。

Intel 18A制程是首个在美国开发和制造的2nm级节点,通过RibbonFET全环绕栅极晶体管和PowerVia背⾯供电两⼤技术突破,将芯片的能效和密度推向新的高度,前者让架构师能够更精确地控制电流,后者提升了电力传输和信号完整性。
相比Intel 3,Intel 18A每瓦性能提⾼15%以上,晶体管密度提升了30%。

至此,英特尔成为业界第一家在⼤规模量产节点上结合全栅极环绕与背⾯供电的公司。
三星、台积电的2nm级制程同样采⽤全环绕栅极(GAA)晶体管技术,将于今年上市。台积电预计今年在N16节点引⼊背⾯供电技术,三星可能要到明年⾸⽤背⾯供电技术。
Intel 18A将成为英特尔未来三代PC和数据中心产品的基石。其工程师也已经开始研发更先进的Intel 14A等技术。
Panther Lake采用英特尔Foveros-S封装技术,由不同制程⼯艺⽣产的多种模块组成:
- 计算tile(Intel 18A)
- 图形tile(Intel 3/台积电N3E)
- 平台控制器tile(台积电N6)
- 基础tile(Intel 1227.1)
- 填充tile(⽤来维护整块芯⽚的完整性)
该处理器专为Agentic AI设计,端侧AI算⼒多达180TOPS,LPDDR5x带宽最多9600MT/s、容量最多96GB,跑大语言模型比AMD HX 370快4.3倍、比酷睿Ultra 200H快2.0倍。
- CPU:10TOPS,速度快,适合跑轻量级AI
- GPU:120TOPS,带宽⾼,适合跑游戏、创作类AI任务
- NPU:50TOPS,能效⾼,适合跑AI助⼿

Panther Lake的AI加速专⽤单元NPU 5聚焦⾼能效,面积比上一代更小,简化了后端功能,通过MAC阵列规模翻倍,把单位⾯积性能提升40%以上,并原生支持E4M3和E5M2两种FP8数据格式。
同时,50TOPS的低功耗NPU可实现始终在线、始终推理,覆盖视频会议、安全等典型场景。
在异构硬件架构的基础上,英特尔通过深度软件优化实现了CPU、NPU、NPU的协同增效。
将OpenVINO与最高96GB的系统内存结合起来,第三代酷睿Ultra可在32K上下文长度下运行700亿个参数的模型。
此前在中国2025英特尔行业解决方案大会上,英特尔还透露,经过在稀疏注意⼒、推测解码、KV Cache压缩等一系列关键技术创新,Panther Lake已经能够可支持800亿参数、32K上下文窗口的MoE混合专家模型,且首词响应时间在30秒内,跑智能体应用的token吞吐率提升至原先的2.7倍。
二、多种配置,统一封装,软硬件联合提升能效
Panther Lake几乎每一个SoC子系统上都实现了重大改进。
英特尔为Intel 18A重新设计了核心,使其在更低电压下运行,实现单核性能提升的同时,进一步提高能效。通过最多增加8个能效核(E核),英特尔提升了第三代酷睿Ultra的多核性能。
相较Lunar Lake,Panther Lake性能提升60%,即便在使用更少性能核(P核)的情况下,也比其此前性能最高的SKU更快、更高效。

低功耗子系统同样被重构,引入带有独立缓存的低功耗能效核(LP-E核),用于运行数百种以批处理和续航为目标优化的工作负载,例如网页浏览和视频会议,能实现更高性能、更低功耗、更长续航。
在平台层面,英特尔部署了多项围绕能效的技术,包括英特尔智能显示、情境感知充电、低功耗视频会议图像处理,以及基于英特尔Wi-Fi的长时连接能力。
通过先进封装技术,英特尔在同一封装形态下提供多种配置的第三代酷睿Ultra,为客户带来了更大的设计灵活性,包括更多内存选择、自定义供电方案的能力。

16核CPU+12 Xe3配置额外扩展了8条PCIe 5.0通道,增强了对⾼性能设备的连接能⼒。

关于Panther Lake的更多配置及技术细节,以及该芯片如何实现高性能与高能效的兼顾,可参见《》一文。
三、公布最大集成GPU,支持AI多帧生成
同时,英特尔公布新一代集成GPU——Arc B390。

它拥有多50%的图形单元,缓存容量翻倍,并集成了96个XMX AI加速单元,可提供120TOPS的图形AI算力。
相比Lunar Lake,Panther Lake在游戏性能上提升了70%,在AI推理性能上提升了50%,让PC玩家能够在轻薄本上体验到接近独立显卡级的游戏性能。

实测结果显示,全新Arc GPU不仅能够持续提供流畅的游戏体验,在功耗和内存配置相近的条件下,相比AMD Radeon最新产品,平均帧率高出70%,在部分游戏中甚至达到2倍。
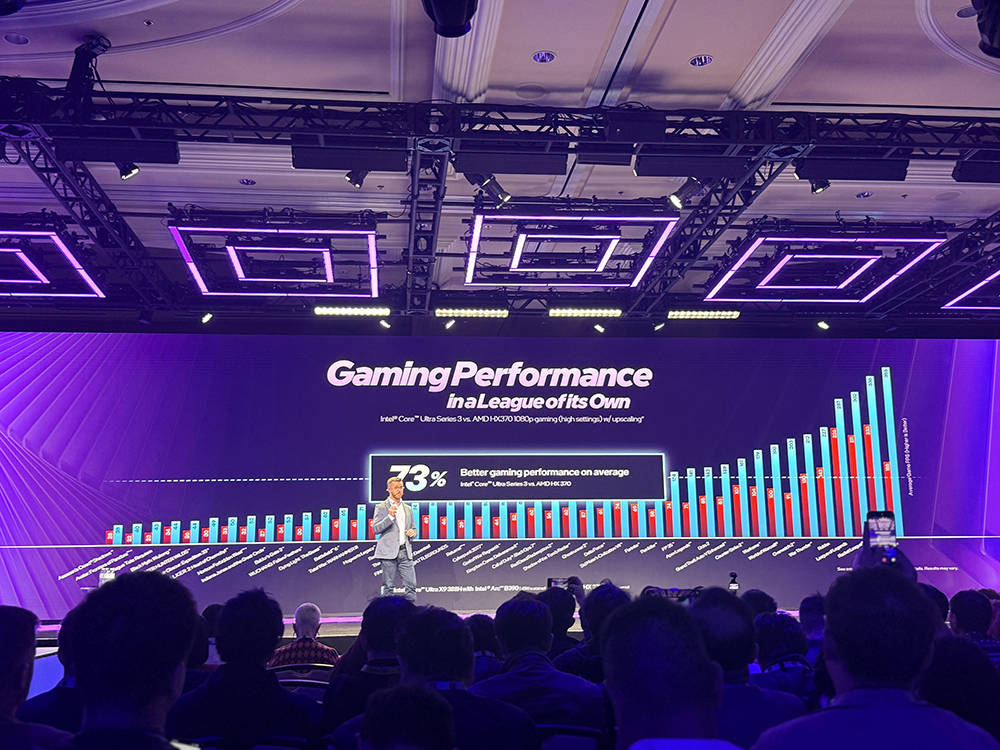
以《Painkiller》和《三角洲行动》这类第一人称射击游戏为例,在10W TDP、高画质设置并开启XeSS超分辨率的情况下,第三代酷睿Ultra都能实现出色的表现。

第三代酷睿Ultra图形架构真正独特之处在于,它是为未来而设计的,英特尔称之为“现代渲染”。

这意味着在开启光线追踪等高负载视觉效果时,可实现更好的光照质量;通过更高质量的纹理和更复杂的几何资产,可带来更锐利的画面;通过AI生成帧,可实现极致流畅的体验。

英特尔新一代Arc是全球首款在首发即支持AI多帧生成的集成显卡:每渲染1帧,就由AI生成3帧。
因此,它可以实现4倍帧率,让3A游戏可在高画质下流畅运行。
一个典例是去年年底发布的《战地6(Battlefield 6)》。英特尔与EA展开了深度合作,在游戏中最高负载的 “Overkill” 画质设置下,Arc B390已经可以通过超分辨率实现流畅体验。
在驱动中开启多帧生成后,其帧率可以扩展到120FPS以上,几乎是AMD处理器的3倍。

目前全球有超过300款游戏支持XeSS技术。
北京AI游戏创企新智慧游戏研发的一款AI应用GameSkill CS2 AI教练,也出现在了英特尔展区。这是一款针对CS电竞职业战队技战术复盘的端侧AI产品,通过AI技术优化训练效率,加快教练和分析师对赛训或职业赛事的复盘速度,并基于英特尔酷睿Ultra系列芯片XPU架构及ARC显卡做了深度优化。
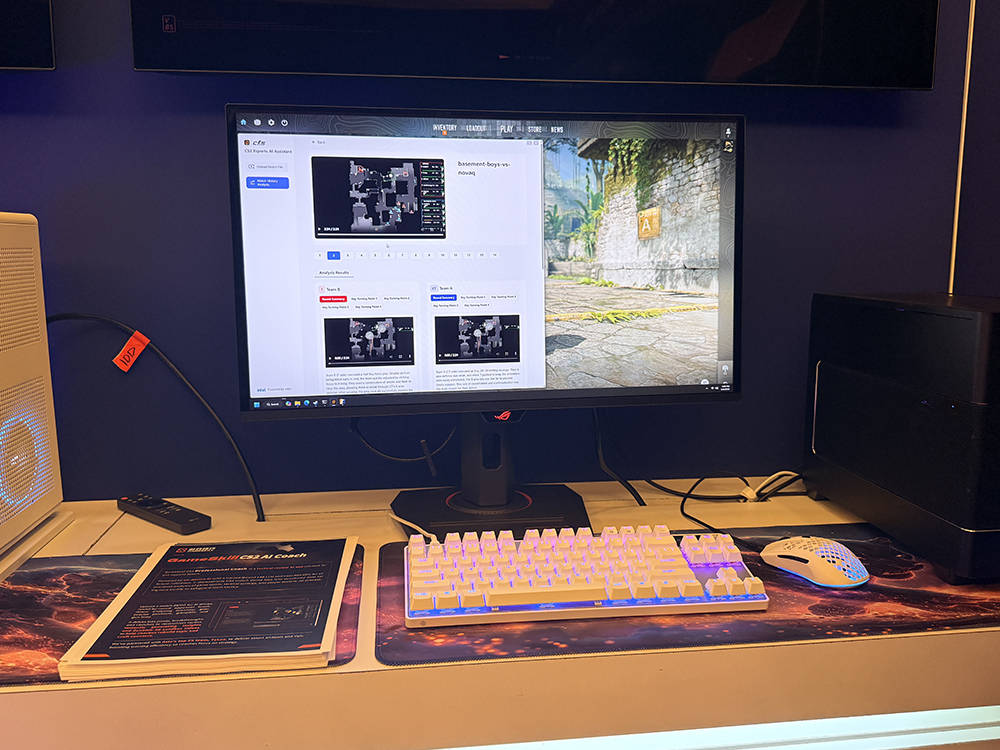
在英特尔技术团队的支持下,GameSkill CS职业AI教练采用全端侧方案,技术团队通过对上万回合游戏对局的数据进行分析处理,对Qwen3-14B模型进行微调训练。全部推理过程跑在Intel B60显卡上,生成战术复盘。
四、混合AI是大势所趋
将整个技术栈放在一起,从硬件、软件、操作系统到固件,英特尔正站在行业前沿,重新定义客户端AI计算的平台基础,让本地智能真正落地于包括PC在内的各类边缘设备。
据悉,英特尔在边缘侧出货的算力规模超过4 ZettaOPS,相当于40个数据中心的计算能力。

关键在于,如何更高效地激活这些算力?
英特尔认为,混合AI是大势所趋,要将这一模式真正落地,需要使端侧模型与云端模型更好地协同工作。
本地AI负责在设备上安全地执行任务,确保数据留在本机;云端AI承担全局推理、规划及多智能体编排。两者之间的通信,带来了更高的安全性、更好的隐私保护、更优的性能,以及更低的成本。
值得一提的是,字节跳动是本场演讲中唯一独占一张PPT的中国合作伙伴。

字节跳动在2025年推出了剪映(CapCut)中的AI粗剪云端功能,用于自动剪辑生成符合故事逻辑的短视频摘要,预计今年将覆盖百万级用户,但这对云端算力造成了巨大压力。
意识到这一点后,字节跳动将英特尔AI PC上的大规模算力与云端协同使用,结果,实现了同样的质量、更快的视频剪辑速度,同时产品的运营方由于降低了云端的算力需求能降低运营成本。
在数据中心基础设施日益受限的背景下,越来越多的AI工作负载将向边缘迁移,但它不会完全脱离云端,而是需要与云无缝协作。
第三代酷睿Ultra系列处理器,正是这种混合AI时代的起点。
此外,英特尔强调会在第一时间优化与支持用户在PC本地运行主流AI模型,并拿中国市场举例,去年在酷睿Ultra上对阿里巴巴最新的Qwen3大模型实现了Day0支持,开发者可以即插即用。

英特尔正与生态系统合作伙伴积极协作,把原本仅依赖云端的解决方案,扩展为混合架构。
同时,英特尔在软件工程和基础设施方面进行了大量投入,支持数百家领先的ISV,提供在英特尔CPU、GPU、NPU上优化AI应用所需的工具。

例如Adobe Premiere Pro正在使用Arc GPU来进行媒体搜索。只需描述你想找的内容,系统就能帮你找到对应片段,即便素材没有标注,或者深埋在大量视频中。
再比如Zoom,推出了虚拟补光灯功能,其模型运行在低功耗NPU上,在提亮人物画面的同时,自动压暗并弱化背景。

英特尔确保软件能够运行在最完整的一组框架和工具之上,并支持主流的行业部署路径,如LLaMA.cpp和PyTorch;OpenVINO工具在各类计算引擎上提供了可直接投入生产的深度优化;英特尔还将关键的开源优化深度集成进微软Windows ML之中。

此外,英特尔也是Copilot+的重要上市节奏合作伙伴。Copilot+将随第三代酷睿Ultra全系列产品一同推出。

结语:为未来AI原生PC而设计,围绕智能体和多模态感知进化
总的来说,第三代英特尔酷睿Ultra处理器提供更长的续航、更快的图形性能、更高的整体性能、更多的AI能力,而且无需等待。
端侧AI计算是大势所趋。从英特尔提出AI PC概念至今,AI PC的发展逐渐从“AI增强型PC(传统应⽤+AI插件)”向“AI原生PC”演进。
AI PC的感知、认知、执⾏、记忆、学习五⼤能⼒协同进化,正带来⼀个智能体应⽤新时代。
未来的AI原⽣PC将进化为拥有多模态感知能⼒的伙伴。其交互将不再局限于键⿏,⽽是基于语⾔、屏幕与摄像头的⾃然互动,具备更深度的感知和理解能⼒。
如今,英特尔正站在客户端AI计算的战略拐点。
第三代酷睿Ultra通过制程、封装、架构全面升级,实现了多维度性能增长和整体能效优化,并正在通过OEM及ISV伙伴的创新设计,支撑更多智能体验在端侧AI设备中普及。

