我们现在所处的不是AI时代,而是一个生成式AI时代。
是的,正如黄仁勋在台北电脑展2024展前演讲中所说,生成式AI技术正在不知不觉中影响着我们的生活与工作。而早在2014年就提出CUDA(通用计算平台)概念的英伟达,已经尝到人工智能带给它的甜头。
市值从1万亿美元到2.7万亿美元,英伟达仅仅用了一年左右的时间。从纸面数据来看,英伟达毫无疑问是这场AI革命的最大赢家,并且它还在这条道路上不断前行。
6月2日晚,Computex 2024(2024台北国际电脑展)在台北贸易中心南港展览馆正式举行,英伟达创始人和CEO黄仁勋登台发表了主题为“Don't Walk”的主题演讲,向全球系统且全面的展示了英伟达在加速计算和生成式AI的最近成果,同时分享了人工智能时代如何助推全球新产业革命。

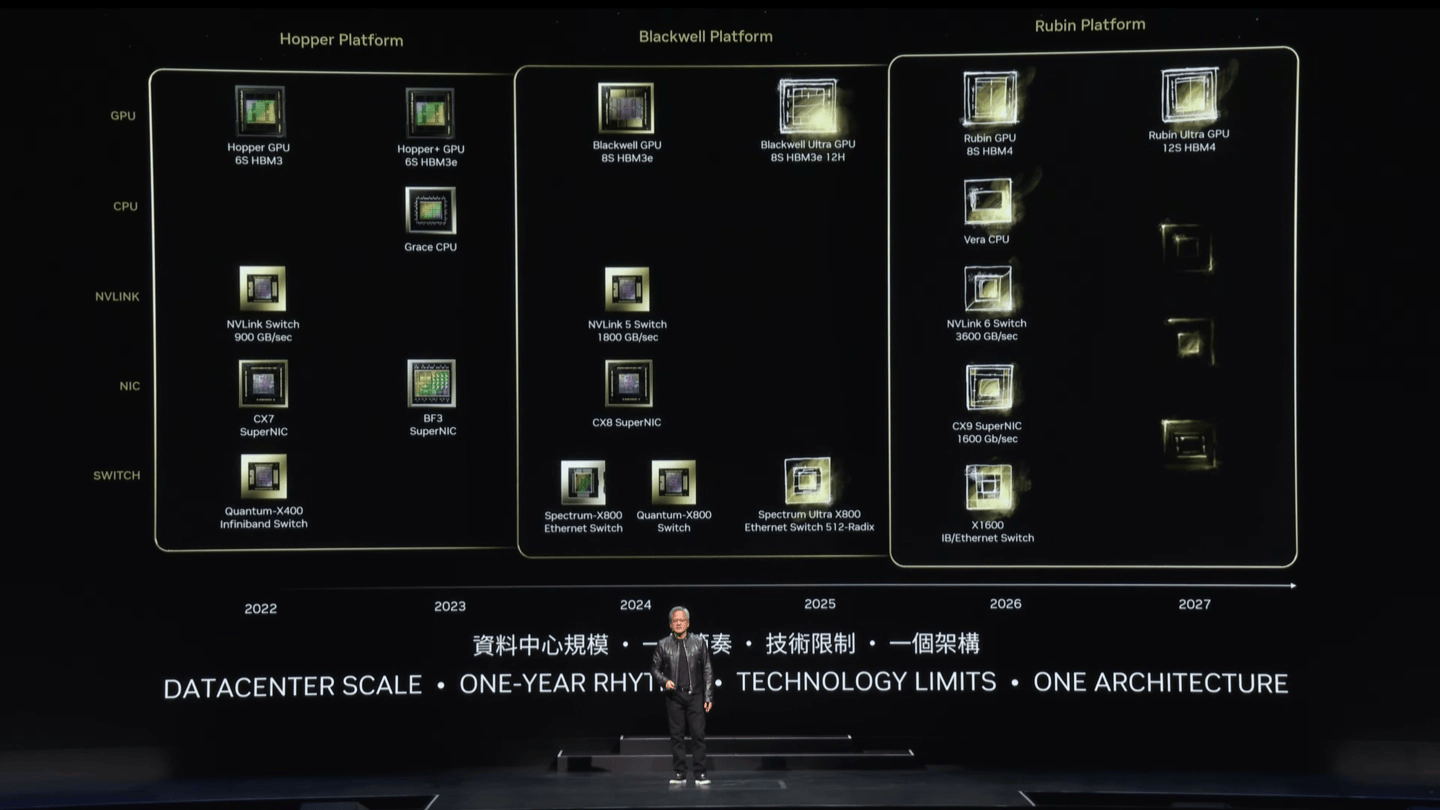
在这场两个小时的演讲中,黄仁勋宣布“全球最强大的芯片”Blackwell芯片正式投产,并表示将在2025年推出Blackwell Ultra AI芯片,2026年发布下一代全新架构Rubin,2027年继续推出升级版Rubin Ultra,以及英伟达在GPU、CUDA、NIM等不同阶段的产品线历史。
老黄这一套连招下来,相信不少人已经被庞大的信息量砸得晕晕乎乎,那么英伟达即将给AI产业带来什么改变?一起来看看。
一年一更,英伟达GPU架构加速迭代
英特尔和英伟达在不少领域面临竞争关系,英特尔CEO帕特·基辛格不止一次在公开场合发表过自己对英伟达的看法,在某次采访中,基辛格感叹英伟达在人工智能领域“非常幸运”地占据了主导地位,并表示英伟达的“地位”本应该属于英特尔。
英伟达在人工智能领域的主导地位究竟是不是运气使然?这次黄仁勋公布的新架构路线图或许正是最好的回应。
由英特尔创始人之一戈登·摩尔提出的摩尔定律,其核心内容为处理器性能大约每两年翻一倍,同时价格下降为之前的一半。而英伟达直接将GPU架构的更新频率从两年一次更新,加速到一年一次。咱就先不说成本的事,就这更新频率,大有掀翻摩尔定律的势头。当然,从7nm制程开始,一直有人说“摩尔定律已死”,最典型的就是英伟达CEO黄仁勋,英伟达能否给这个讨论定下结论,让我们共同期待。
回到产品本身,Blackwell B200是NVIDIABlackwell架构首款新产品,基于台积电的4nm工艺打造,采用了将两个Die连接成一个GPU的双芯设计,因此每个GPU芯片上拥有2080亿个晶体管,比起上一代GH100 GPU上的800亿个晶体管,Blackwell B200 GPU算是一次相当大的突破。
在B200的基础上,英伟达还推出了由两个BlackwellB200 GPU和一个基于Arm的Grace CPU组成的完全体AI芯片组:Blackwell GB200。该架构主要是为了满足未来AI工作负载的需求,为全球机构运行实时生成式AI提供了可能,而且其成本和能耗只有上一代Hopper GPU架构的二十五分之一。
虽然黄仁勋没有透露2025年计划推出Blackwell Ultra的具体情况,但参考Blackwell在性能、成本和能耗方面的提升,同架构升级版本的表现让人无比期待。
来到2026年,命名源于美国女天文学家Vera Rubin的下一代GPU架构Rubin即将面世,将首次支持8层HBM4高带宽存储。届时代号“Vera”的CPU将于Rubin GPU一同推出,组成Vera Rubin芯片。此外,Rubin平台还将搭载新一代NVLink 6 Switch,提供3600GB/s的连接速度,以及1600GB/s的CX9 SuperNIC,以保证高效的数据传输。

根据爆料,Rubin架构首款产品为R100,采用台积电3nm EUV制造工艺,四重曝光技术,CoWoS-L封装,预计2025年第四季度投产。
2027年,升级版“Rubin Ultra”,HBM4内存升级为12堆栈,容量更大,性能更高。
至此,英伟达未来4年的宏伟蓝图正式向我们展开,这一战略规划一直延伸到2027年,英伟达提前公布的方式尽显自信。自信来源于底气,黄仁勋在演讲中直接将英伟达定义为全球生成式AI浪潮的来源及推动者:
人工智能崛起之所以有可能,完全因为我们相信只要让强大的计算变得越来越便宜,总会有人找到巨大的用途。正因为我们利用特定算法将计算边际成本降低了100万级别,今天使用互联网上的所有数据来训练大模型才成为了所有人默认合乎逻辑的选择,不再有人怀疑和质疑这个做法。而在英伟达这么做之前,没有人预料到,没有人提出这样的需求,甚至没有人理解全部潜力。
我们很难评判这番言论的对错,但英伟达对全球生成式AI产业的贡献大家有目共睹,其主张的CUDA已经达到了相对成熟阶段,随着CPU性能增长放缓,利用CUDA等技术加速计算任务又将成为应对计算需求的新宠儿,生成式AI也将成为全球下一次革命性的技术变革。
英伟达还有什么护城河?
在演讲中,黄仁勋还介绍了Earth-2 数字孪生地球、Isaac机器人平台、nference Microservices等一系列AI工厂的内容。随着业务的不断扩展,我们似乎很难用一个或几个词来概括这家万亿市值级别的芯片巨头了。
过去提起英伟达的优势,大家最熟悉的必然是GPU、CUDA......,大体可以归纳为软件构建生态,硬件堆砌算力。说到这里,又要请出老熟人英特尔CEO帕特·基辛格,因为他在酷睿Ultra发布会上表示:英伟达CUDA护城河又小又浅。
来到生成式AI时代,如果CUDA真如基辛格所说,无法成为英伟达的技术护城河,那么英伟达还能依靠什么呢?我想答案或许是AI网络。
去年5月,英伟达在COMPUTEX 2023上发布了全球首个专为人工智能(AI)设计的高性能以太网架构Spectrum-X,其主要面向生成式AI市场。据介绍,Spectrum-X拥有无损网络、动态路由、流量拥塞控制、多业务性能隔离等主要特性,能降低大模型训练成本、缩短训练时间。
AI大模型之所以称之为大,不仅是因为模型参数量大,还有日常训练所需的庞大数据,这些先决条件导致大模型的训练成本极高。
4月初,OpenAI的竞争对手Anthropic的首席执行官达里奥·阿莫代伊接受采访时指出,目前市场上人工智能模型的培训成本已高达约1亿美元,预计到了2025年和2026年,这一成本将飙升至50亿或100亿美元。
其中的大部分费用被GPU消耗,以英伟达Blackwell处理器为例,训练一个拥有1.8万亿参数的AI大模型需要大约2000个BlackwellGPU,如果将GPU换成Hopper,则大约需要8000个。
因此,不少企业选择打造成千上万GPU互联的AI数据中心,其实也就是黄仁勋所说的AI工厂,只不过这个工厂生产的产品是训练好的大模型。整体算力优势能有效降低训练成本,减轻企业从头搭建AI大模型的复杂步骤,简单来说,就是AI大模型训练外包。
除了AI数据中心外,另一个方法就是前面提到的网络架构。区别于传统网络,面向AI计算的网络架构就是为了解决单一数据中心超载,从而需要多个地区的数据中心协同工作而存在的。

从技术层面来看,Spectrum-X针对AI计算的高稳定性要求,进行了针对性优化,也就是多种软硬件技术组成的系统级网络架构,以解决AI训练过程中N个GPU同步运行的负载,以及处理突发流量的能力。
随着生成式AI的发展,数据量需求必然剧增,当纯GPU和单一数据中心不足以解决数据负载问题时,成熟的网络架构就会成为英伟达下个技术护城河。或许英伟达在布局时也没有想到,这个原本用于传统云计算的技术会成为生成式AI浪潮的关键。
写在最后
英伟达公布的截至2024年4月28日的2025财年第一财季财报显示,英伟达期内实现营收260.44亿美元,同比上涨262%;净利润148.81亿美元,同比上涨628%。财报数据公布后不久,英伟达股价迅速上涨,据统计,在过去的2023年中,英伟达股价涨幅超230%,今年以来涨幅已达到121.39%。
可以说,全球AI算力芯片龙头,被称为“AI时代卖铲人”的英伟达在这轮生成式AI浪潮中赚得盆满钵满,也难怪老黄在演讲时春风满面。现在,英伟达的“卡”供不应求,不只是字节、百度等中国科技巨头在抢着囤卡以应对极端情况,硅谷科技巨头如微软、Meta,也全都在找英伟达买卡。

事实上,入局AI以及AI芯片的玩家越来越多,OpenAI以及谷歌等AI巨头也将AI产品的竞争方向从大语言模型转向多模态模型。可以预见的是,接下来几年企业训练AI的算力需求还会冲上一个新高峰,英伟达作为当前AI算力芯片领域的巨头,持续增长几乎是板上钉钉的事情。
当然,谷歌、OpenAI等玩家都在通过自己的方式试图打破英伟达的算力霸权,短时间内或许很难实现抗衡,但市场不会坐视任何企业一家独大,所有玩家都会继续挑战英伟达,直至成功。
英伟达能否再续辉煌,一年一款大更新带来的效果究竟会有多惊人,我们很快就能知道答案。

